Connect Google BigQuery to Data Pipelines
Learn how to connect Google Big Query to Data Pipelines.
BigQuery is Google's flagship a data warehousing platform, popular with developers, analysts and marketers with a recent native integration into GA4, the newest edition of Google Analytics.
Here's how to connect BigQuery to Data Pipelines.
Part 1: Allow access to Google Cloud
Go to the Google Cloud Dashboard
Select APIs & Services
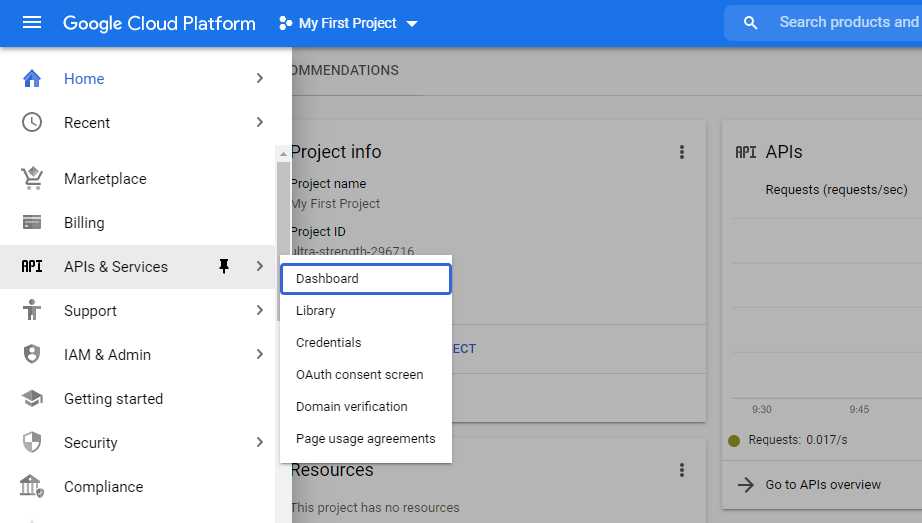
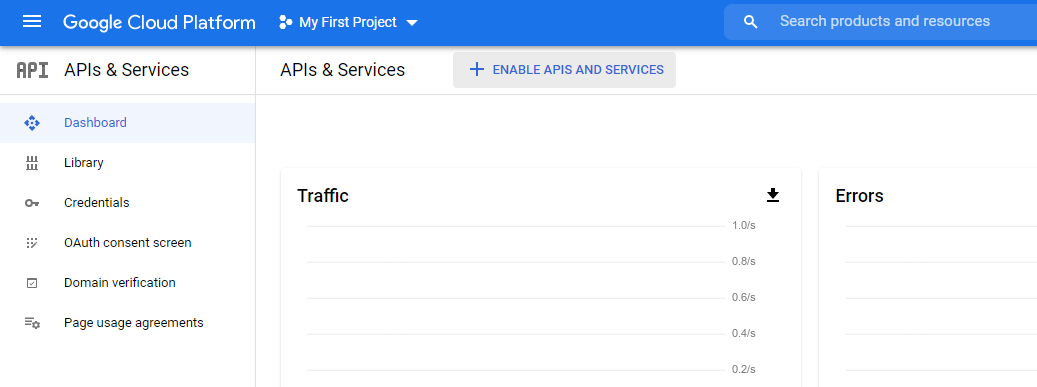
Click + Enable APIs and Services
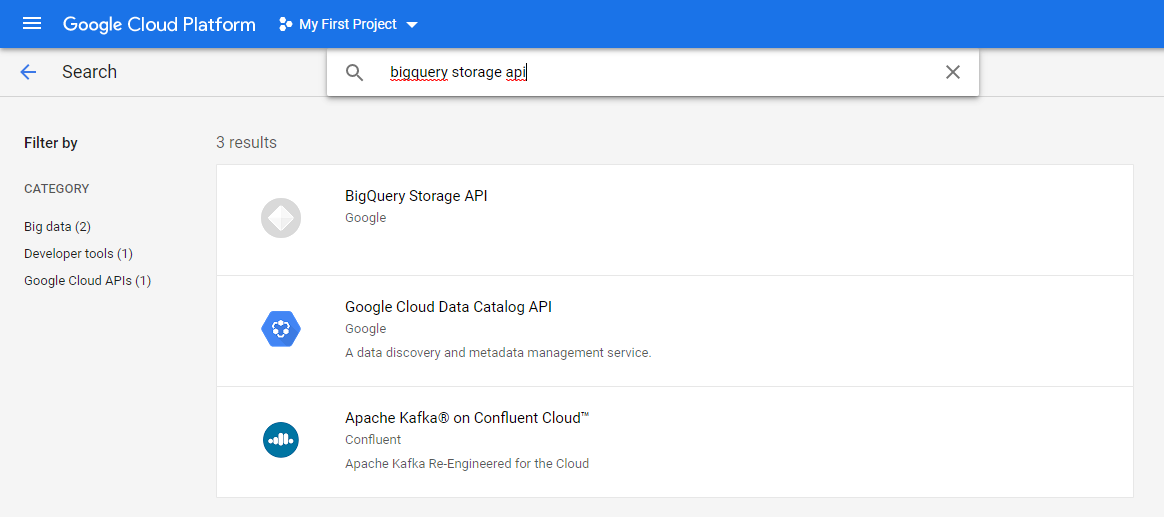
Search for "bigquery storage api" then select it
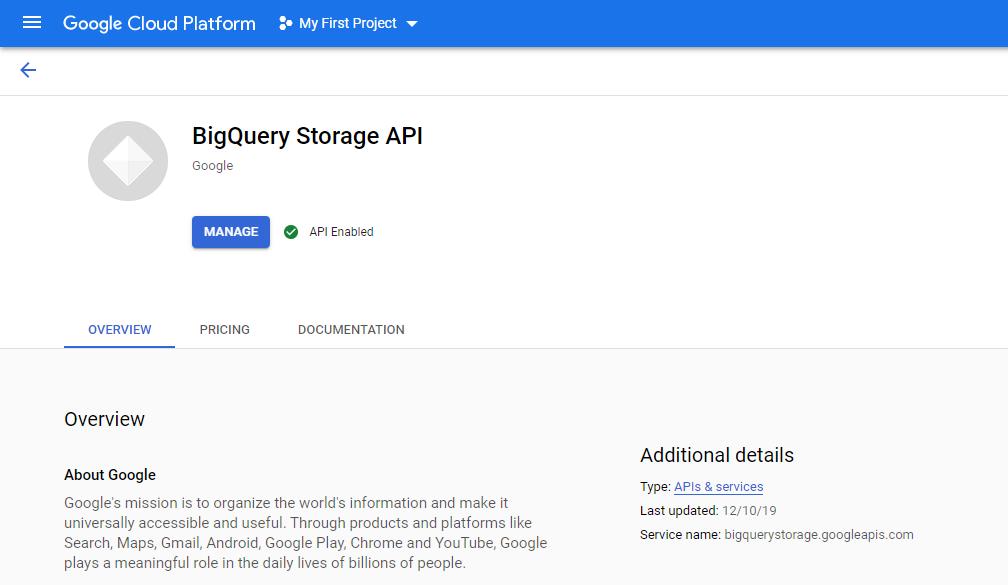
If it's not enabled, enable it
From the main dashboard go to IAM & Admin -> Service Accounts
Click Create Service Account
Name your service account and click Create
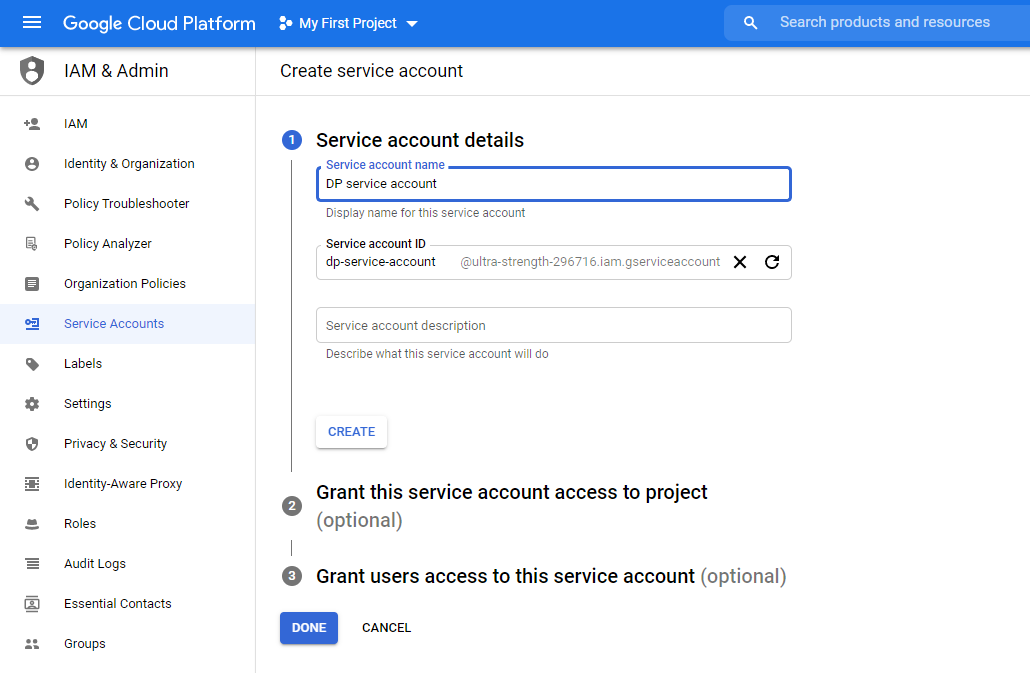
Add following two roles
- BigQuery Data Editor
- BigQuery User
Click Done
You should see the service account in the list. Click "Create Key"
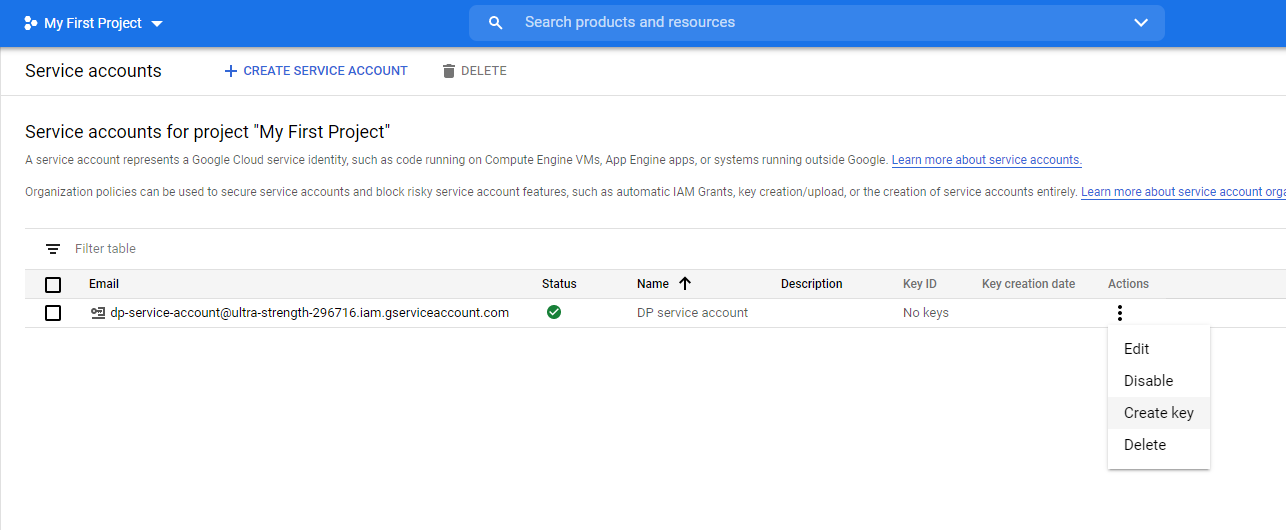
Select JSON key type
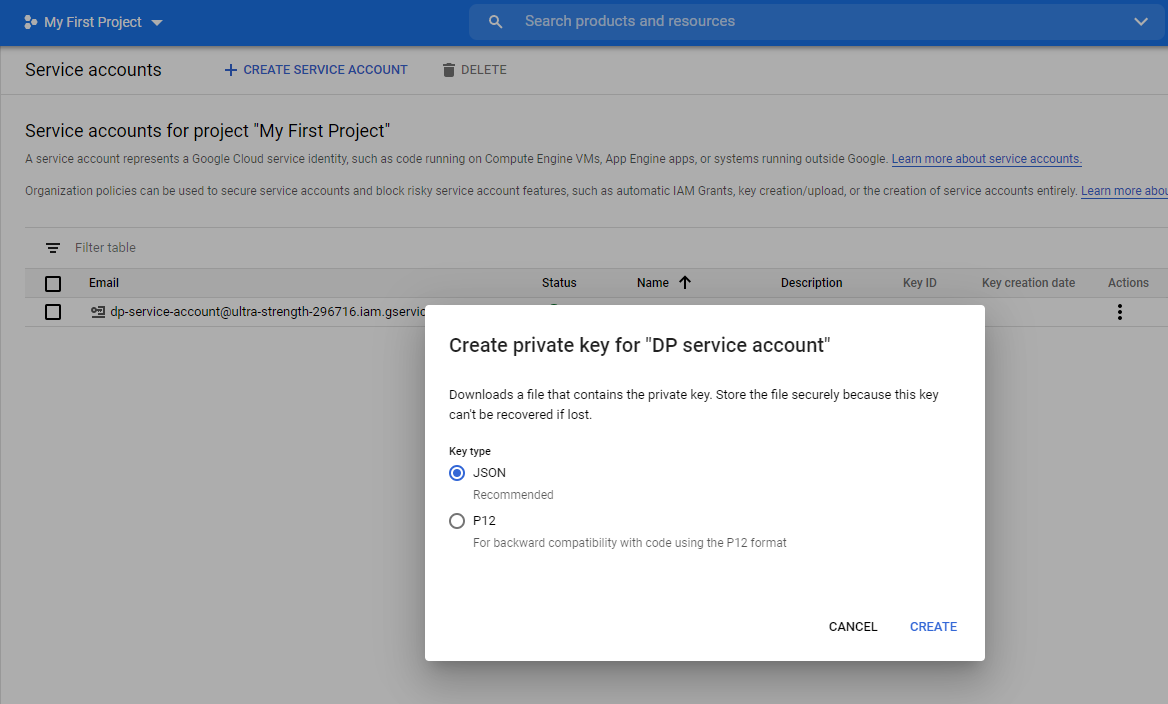
The key is saved. It contains your credentials so keep it safe and secure.
If you do not intend to write to BigQuery you are done with the Google Cloud setup and you can skip PART 2 where we will be creating and configuring a temporary bucket for writes.
PART 2: Create and configure a temporary bucket for writing to BigQuery from Data Pipelines.
From the main dashboard click Storage
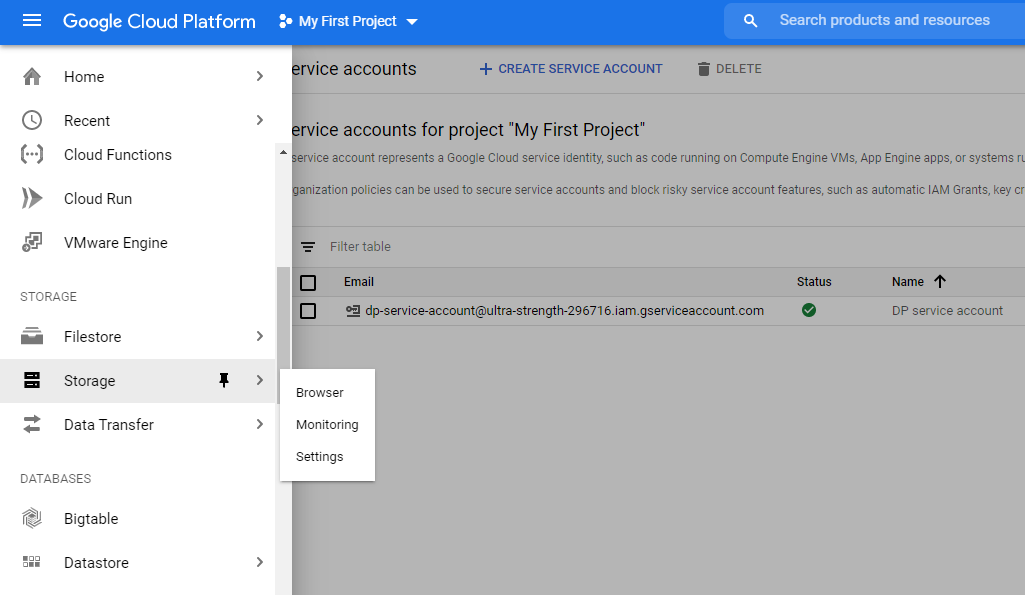
Click Create Bucket
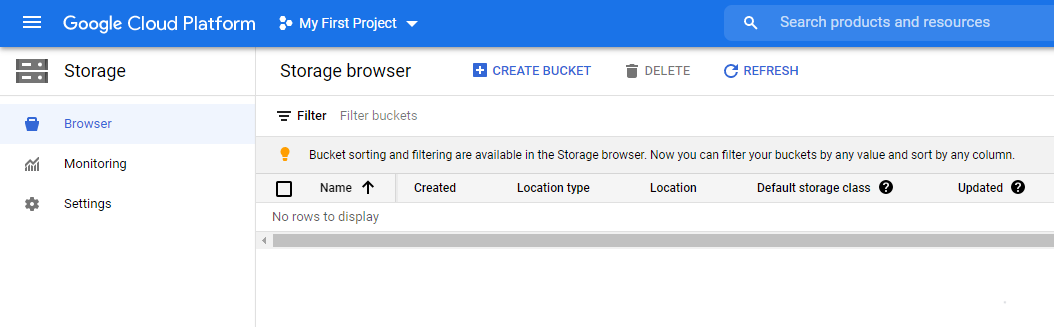
Specify the options then click Create. Remember the name you chose because you will need it later.
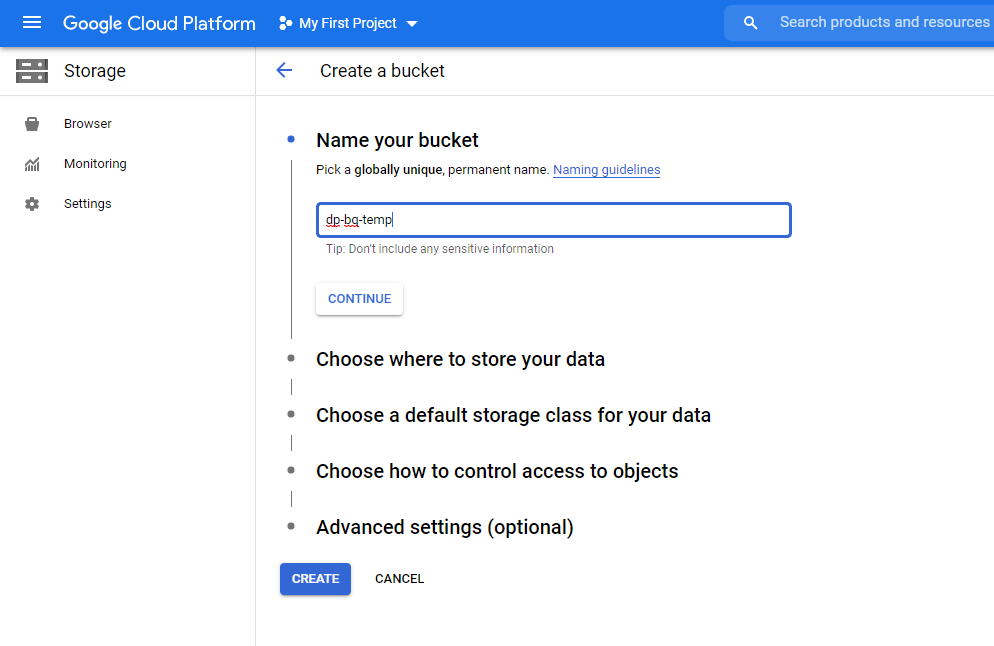
Go to Bucket details and click "ADD" next to Permissions
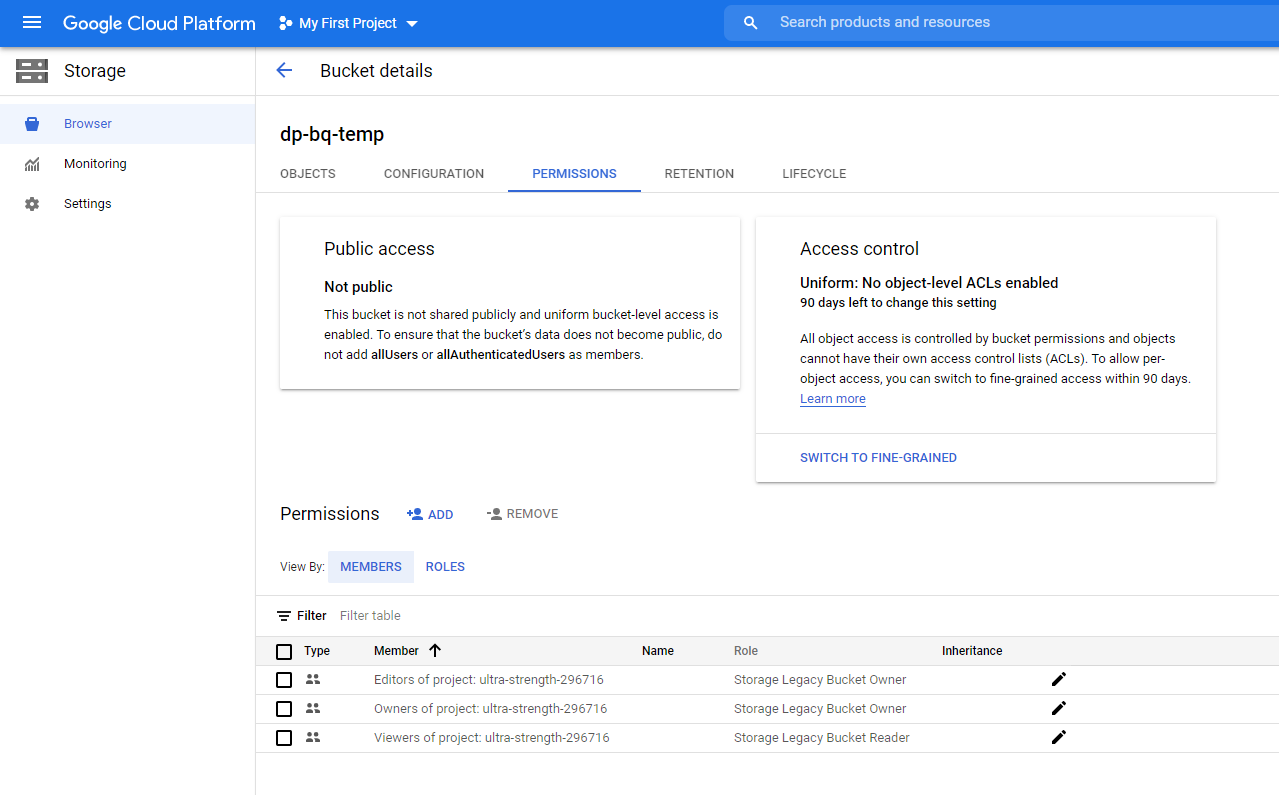
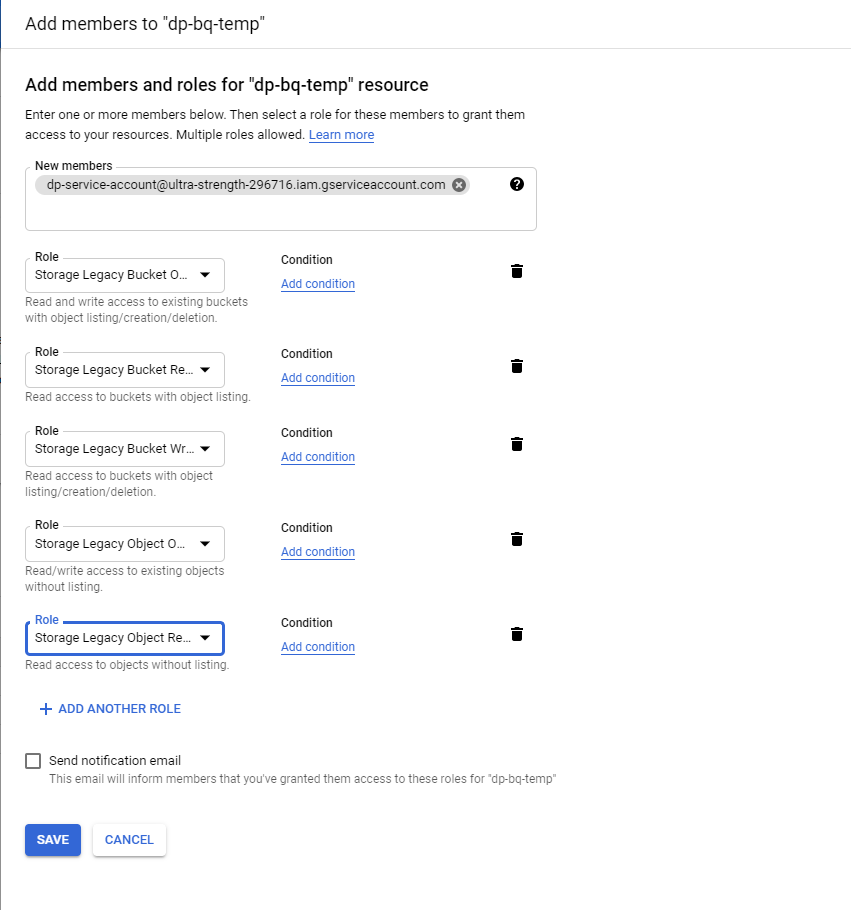
Enter the service account email you created earlier. Select the service account.
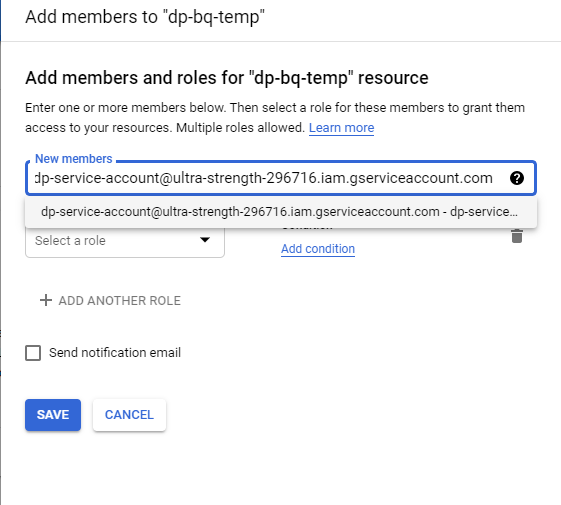
Add the following roles: then click Save
- Storage Legacy Bucket Owner
- Storage Legacy Bucket Reader
- Storage Legacy Bucket Writer
- Storage Legacy Object Owner
- Storage Legacy Object Reader
...remember to click Save
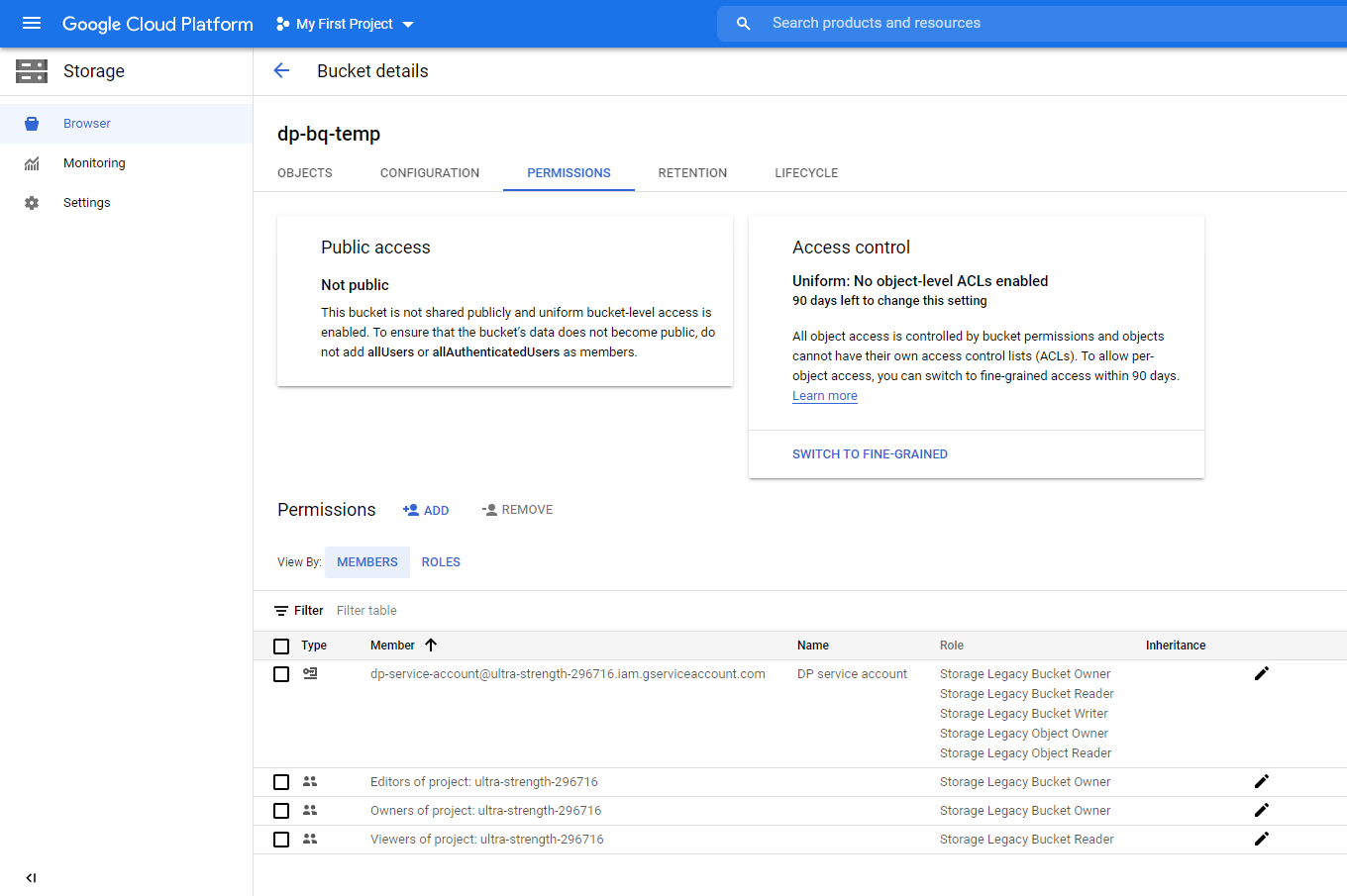
Ensure that all of the roles are showing for the service account
PART 3: Create connect to Data Pipelines
Click Data connections
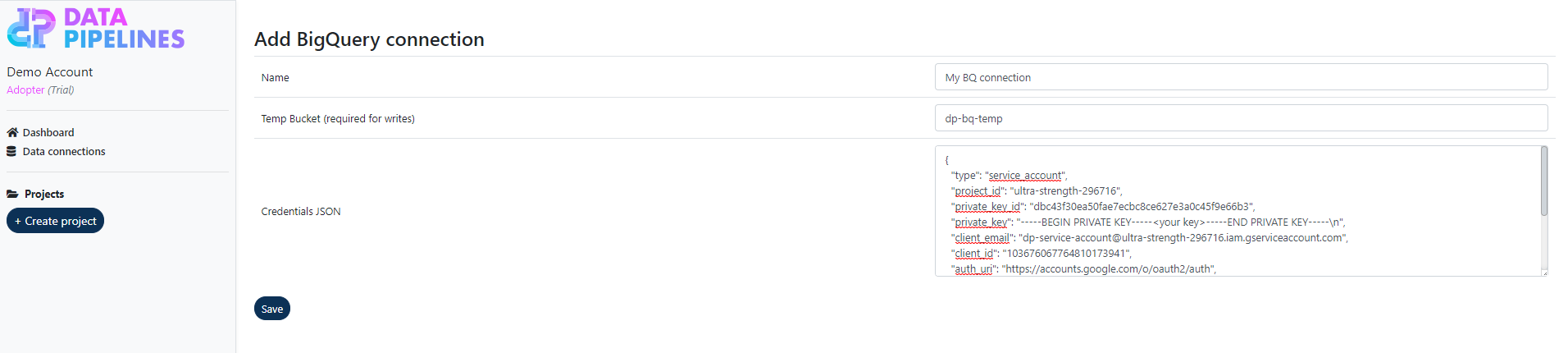
Click Add BigQuery connection
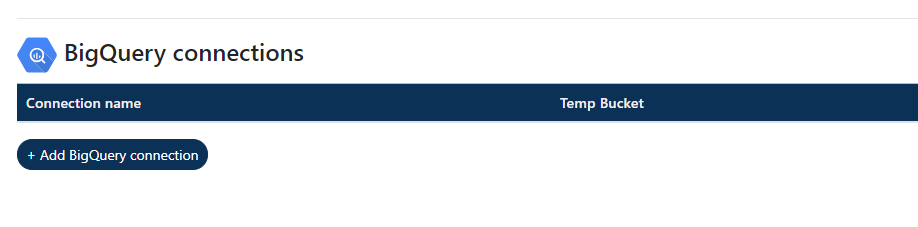
Enter a name for you connection and the name of the temporary bucket (if you created one).
Paste the contents of your json key file. This will be kept securely.
You should now be able to connect to your BigQuery instance via the usual means. Make sure that you always specify the dataset name as well as table name when referencing a table, e.g. <my_dataset.my_table>
