How to use Spark SQL in your data pipeline
Incorporate Apache Spark SQL directly in your pipeline
To process data in an efficient distributed manner and be able to cope with large amounts of data, the Data Pipelines platform uses Apache Spark under the hood.
You don't have to know any Spark SQL to be able to use our platform but the option is there for advanced users familiar with Spark to enter Spark SQL directly in the pipeline builder.
Spark SQL can be applied directly to source datasets as a single step or combined with other transformation widgets as a step in a pipeline consisting of multiple steps.
If you are familiar with Apache Spark then you may find it easier to simply write Spark SQL instead of using the other builder widgets. Note that similarly to some of the other transformations such as join or intersect, the SQL step can be applied to an existing dataset or used to create a new dataset.
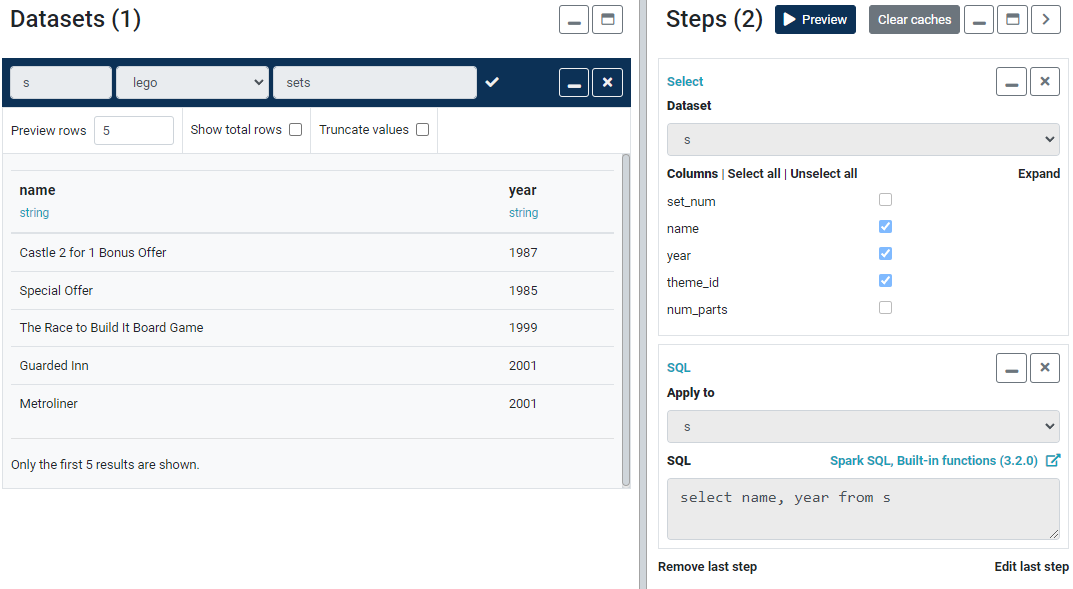
s datasetThe pipeline in Figure 2 has two steps. The first one uses the Select widget, the other applies Spark SQL directly to the result of the first step. Notice how both of these steps are select operations but they are achieved differently. In this example, the Spark SQL is very simple but there is no limit to how complex it can get.
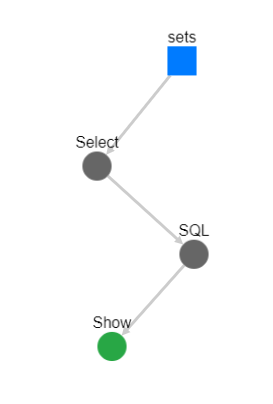
It needs pointing out that Spark SQL operations are displayed as a single step in the DAG (directed acyclic graph) (Figure 3). So if you enter complex queries they will still show as a single step making the DAG view less helpful.
You can reference any dataset in your Spark SQL that has been loaded into the pipeline. Note that there is no need to reference the actual table name, just the alias. So for example, assuming there is a dataset named u in the pipeline you would write select * from u whereas for example in MySQL one would write select * from <tablename> u.
To learn more about Spark SQL refer to the official documentation.