How caching works
How Data Pipelines makes pipeline building efficient by using a cache
I order to make pipeline building quicker, Data Pipelines stores some of your data internally.
Why is it necessary?
Storing data temporarily (caching) serves several purposes. The main reasons to cache data are speed and reduced cost.
How does it work?
After each dataset you load and each transformation step you apply to your pipeline, a small subset of the output data is stored in our system. Input data is never cached.
You may have noticed that when you return to the pipeline builder view, the display of the pipeline's output is immediate. It would be wasteful to recreate this preview every time you visit the builder view. You can clear the cache by clicking 'Invalidate caches' then clicking 'Preview'.
You may have also noticed that when you add a transformation step and then remove it, the previous step's output displays immediately. This output was also retrieved from an internal cache to make pipeline building more efficient.
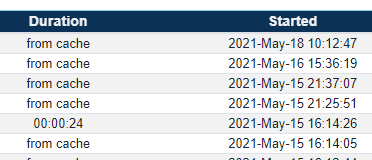
The 'Recent runs' view shows information about the cache in the 'Duration' column. Normally, this column will show the time it took for the pipeline preview to be generated. If the preview was retrieved from cache you will see 'from cache' instead of the duration time.
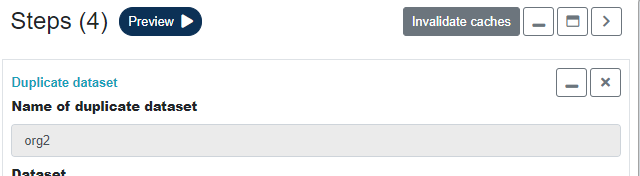
Caches can be manually invalidated for a pipeline by clicking 'Invalidate caches' in the pipeline builder.
Caches are automatically invalidated when a data connection a pipeline uses is updated or deleted.
Is the cache used for scheduled runs?
No. Caches are only used when building a pipeline. When your pipeline is run by the scheduler it will always generate output using current data.
Is my data kept securely?
Yes. Cached output data is stored internally in a secure database.