Mix pipeline builder widgets and native Spark SQL
Data Pipelines allows you to mix pipeline builder widgets and native Spark SQL in the same pipeline
Data Pipelines provides builder widgets for the most common data transformations, such as Select, Filter and Join. It is possible to use widgets and Spark SQL within the same pipeline.
Example use case: create a pipeline that finds all rows from last week and counts them. This number is then written to a Google Sheet via a schedule every Monday.
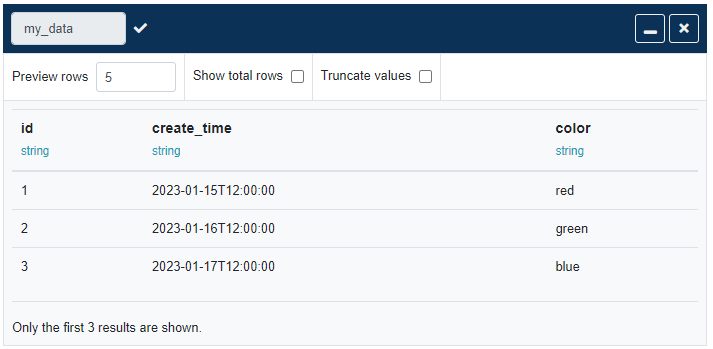
For the above use case, we want to calculate the week start and week end dates dynamically, based on the current date. This is possible using built-in Spark functions, such as dayofweek and current_date, however, it needs specialised knowledge of Apache Spark functions that most users will not have.
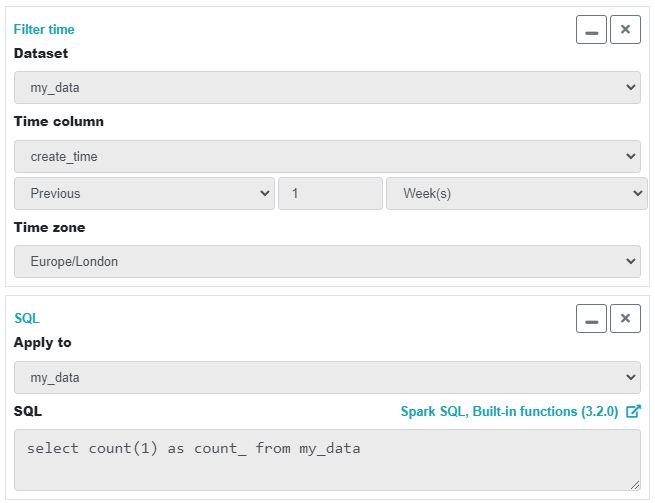
It is much easier to use the built-in 'Filter time' Data Pipelines widget. This widget has presets for common timeframes including 'Previous 1 week'.
With the rows filtered, we now just need to count the rows but Data Pipelines doesn't have a 'Count' widget*. We can, however, add an SQL transformation step and write a Select statement manually. Notice how the SQL statement is just plain old engine-agnostic SQL and doesn't require specialised knowledge of Spark functions.
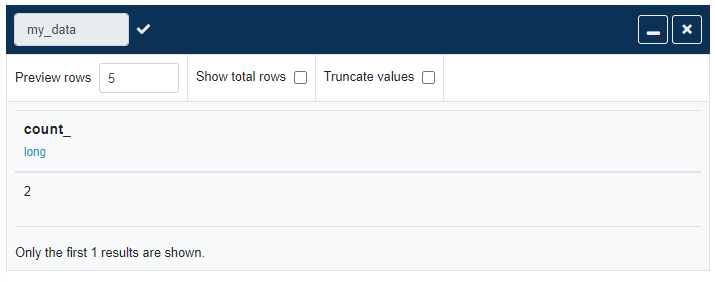
The result is just another dataset that can be transformed further or, like in this case, written to our destination Google Sheet.
The above example is extremely simple but the principle can be applied to much more complex pipelines.
The ability to mix convenient Data Pipelines builder widgets and Spark SQL in the same pipeline makes pipeline creation quicker, easier and more powerful than using one or the other on their own.
*The reason for this is that count() is an Apache Spark Action and not a Transformation. More about this here.